SpringCloud Alibaba
1、服务注册与发现 - nacos
1.1、nacos注册中心部署
单机模式 - 用于测试和单机试用。
集群模式 - 用于生产环境,确保高可用。
多集群模式 - 用于多数据中心场景
1.1.1、单机部署
1、下载地址:https://nacos.io/,解压
2、修改配置conf/spplication.properties
1 | spring.datasource.platform=mysql |
3、初始化数据库
执行conf下 mysql-schema.sql 初始化数据库
4、修改bin/starup.cmd(linux下修改startup.sh)
set MODE=”cluster” 改为 set MODE=”standalone”
5、执行启动脚本
6、访问http://127.0.0.1:8848/nacos,输入用户名/密码:nacos/nacos,进入主界面
1.1.2、集群部署
本次部署 3个nacos节点,然后一个负载均衡器(nginx)代理3个Nacos
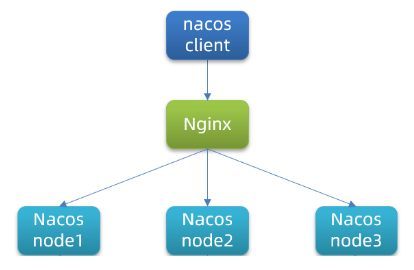
1、三个节点的IP和端口需要配置到cluster.conf文件中。 使用以Nacos自带的cluster.conf.example文件复制一份,作为cluster.conf文件。编辑cluster.conf文件
1 | #it is ip |
5、将nacos文件夹复制三份,分别命名为:nacos1、nacos2、nacos3,然后分别修改三个文件夹中的application.properties里的端口
6、配置nginx负载均衡
1 | events { |
7、在浏览器访问:http://localhost:88/nacos即可
实际部署时,需要给做反向代理的nginx服务器设置一个域名,这样后续如果有服务器迁移nacos的客户端也无需更改配置.
Nacos的各个节点应该部署到多个不同服务器,做好容灾和隔离
1.2、nacos注册中心工作流程
服务注册:Nacos Client会通过发送REST请求的方式向Nacos Server注册自己的服务,提供自身的元数据,比如ip地址、端口等信息。Nacos Server接收到注册请求后,就会把这些元数据信息存储在一个双层的内存Map中(外层key是namespace,内层key是group:service)。
服务心跳:在服务注册后,Nacos Client会维护一个定时心跳来持续通知Nacos Server,说明服务一直处于可用状态,防止被剔除。默认5s发送一次心跳。
服务同步:Nacos Server集群之间会互相同步服务实例,用来保证服务信息的一致性。
服务发现:服务消费者(Nacos Client)在调用服务提供者的服务时,会发送一个REST请求给NacosServer,获取上面注册的服务清单,并且缓存在Nacos Client本地,同时会在Nacos Client本地开启个定时任务(默认35s)定时拉取服务端最新的注册表信息更新到本地缓存
服务健康检查:Nacos Server会开启一个定时任务用来检查注册服务实例的健康情况,对于超过15s没有收到客户端心跳的实例会将它的healthy属性置为false(客户端服务发现时不会发现),如果某个实例超过30秒没有收到心跳,直接别除该实例(被剔除的实例如果恢复发送心跳则会重新注册)
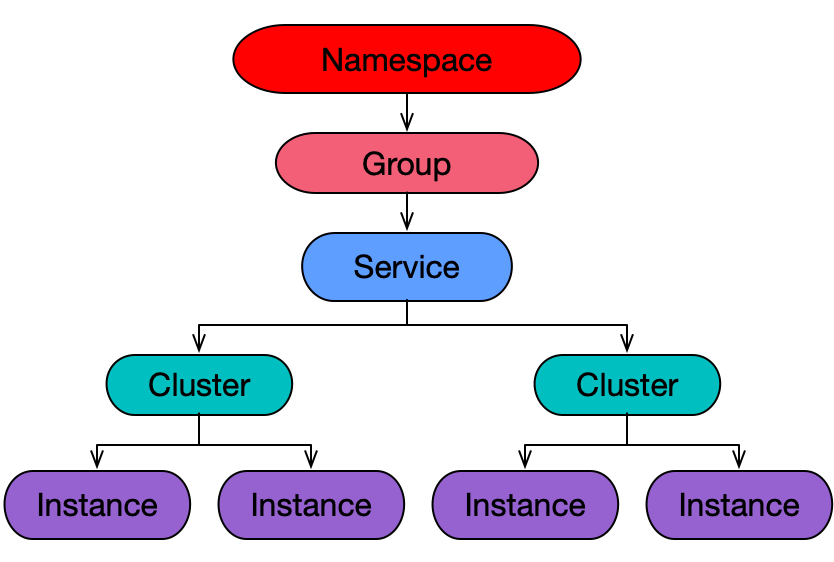
1.3、nacos领域模型
nacos的服务由三元组唯一确定(namespace、group、serviceName)
nacos的配置由三元组唯一确定(namespace、group、dataId)
| 模型名称 | 解释 |
|---|---|
| Namespace | 实现环境隔离,默认值public(一般用于区分测试、生产环境等) |
| Group | 不同的service可以组成一个Group,默认值Default-Group |
| Service | 服务名称 |
| Cluster | 对指定的微服务虚拟划分,默认值Default |
| Instance | 某个服务的具体实例(ip+端口) |
Nacos 服务发现使用的领域模型是命名空间-分组-服务-集群-实例这样的多层结构。服务 Service 和实例 Instance 是核心模型,命名空间 Namespace 、分组 Group、集群 Cluster 则是在不同粒度实现了服务的隔离
2、远程调用 - RestTemplate
RestTemplate是一款Spring框架中的HTTP客户端工具类库,它封装了大量的HTTP请求处理代码,使得我们可以方便地进行HTTP请求的发送与处理。RestTemplate支持多种HTTP请求方式,例如GET、POST、PUT、DELETE等,同时也支持参数的传递与响应结果的解析等功能
下面简单看一下它的三种使用方式:
2.1、直接使用
1 | RestTemplate restTemplate = new RestTemplate(); |
2.2、使用cloud的 LoadBalancerClient 获取服务地址
1 |
|
2.3、Ribbon + RestTemplate
其实就是和cloud的Ribbon负载均衡器整合
1 | // RestTemplate 注解为bean, 并加上 @LoadBalanced |
3、负载均衡器 - Ribbon
实际开发中一般不会让网址直接访问代码服务器(小项目除外),通常是通过nginx进行反向代理和负载均衡.而在Springcloud里我们用了另外2个组件来代替nginx的这两个功能,网关代替反向代理,Ribbon就是代替负载均衡的组件.通常在微服务架构中,业务都会被拆分成一个独立的服务,服务与服务的通讯是基于http restful的.Spring cloud有两种服务调用方式,一种是ribbon+restTemplate,另一种是feign
3.1、Ribbon的工作流程
1、restTemplate的bean添加了@LoadBalanced注解,这个注解就是一个标记,表示这个RestTemplate发起的请求要被Ribbon拦截和处理。
2、Ribbon解析url中的host,获取服务名,根据服务名获取实例列表(先从本地缓存获取,没有再从nacos server获取并缓存实例列表)
3、通过相应的负载均衡策略获取一个实例的ip+端口
4、发起远程调用
3.2、Ribbon均衡策略
Ribbon核心组件IRule:根据特定算法从服务列表中选取一个需要访问的服务;其中IRule是一个接口,有七个自带的落地实现类,可以实现不同的负载均衡算法规则。
负载均衡的实现主要有三种算法:轮询(默认方式)、随机、权值分配,其中轮询 ZoneAvoidanceRule 也是 @LoadBalanced 注解默认的分配策略,细节上可以分为以下几种
| 策略名 | 名称 | 规则描述 |
|---|---|---|
| RoundRobinRule | 轮询策略 | 简单轮询服务列表来选择服务器。 |
| RandomRule | 随机策略 | 随机选择一个可用的服务器 |
| RetryRule | 重试策略 | 正常按轮询,失败后重试机制的选择逻辑 |
| BestAvailableRule | 最低并发策略 | 忽略那些短路的服务器,并选择并发数较低的服务器 |
| WeightedResponseTimeRule | 响应时间加权策略 | 为每一个服务器赋予一个权重值。服务器响应时间越长,这个服务器的权重就越小。这个规则会随机选择服务器,这个权重值会影响服务器的选择 |
| AvailabilityFilteringRule | 可用过滤策略 | 对以下两种服务器进行忽略: (1)在默认情况下,这台服务器如果3次连接失败,这台服务器就会被设置为“短路”状态。短路状态将持续30秒,如果再次连接失败,短路的持续时间就会几何级地增加。 (2)并发数过高的服务器。如果一个服务器的并发连接数过高,配置了AvailabilityFilteringRule规则的客户端也会将其忽略 |
| ZoneAvoidanceRule(默认) | 区域权衡策略 | 综合判断 Server 所在区域的性能和 Server 的可用性轮询选择 Server,并且判定一个 AWS Zone 的运行性能是否可用,剔除不可用的 Zone 中的所有 Server |
3.3、切换负载均衡策略
方法一:
1、创建配置类
1 |
|
2、启动类上加注解
1 |
方法二:
application.yml文件中,添加新的配置也可以修改规则
1 | userservice: |
4、服务调用 - OpenFeign
RestTemplate发起远程调用的代码时会存在一些问题比如:代码可读性差,参数复杂URL难以维护
OpenFeign的设计宗旨式简化Java Http客户端的开发。用户只需创建一个接口并添加相应的注解,即可实现对远程服务的调用。OpenFeign 是 Spring Cloud 的一部分,它支持 Spring MVC 的注解,如 @RequestMapping,使得使用 HTTP 请求访问远程服务就像调用本地方法一样直观和易于维护。OpenFeign集成了Ribbon,实现了客户端负载均衡
4.1、实现流程
1、调用方添加依赖
1 | <dependency> |
2、启动类添加注解@EnableFeignClients
1 |
|
3、调用方定义pai
1 |
|
4、调用方调用pai
1 |
|
5、配置中心 - nacos
5.1、基本概念
微服务下配置文件存在的问题:
1、配置文件分散在每个微服务中,并且每个服务都有不同的环境(开发,测试,生产等),手动维护很困难
2、配置文件无法实时更新,修改配置文件后必须重启微服务才能生效
配置中心的思路是:
首先把项目中各种配置全部都放到一个集中的地方进行统一管理,并提供一套标准的接口。 当各个服务需要获取配置的时候,就来配置中心的接口拉取自己的配置。当配置中心中的各种参数有更新的时候,也能通知到各个服务实时的过来同步最新的信息,使之动态更新
5.2、使用
1、创建namespace
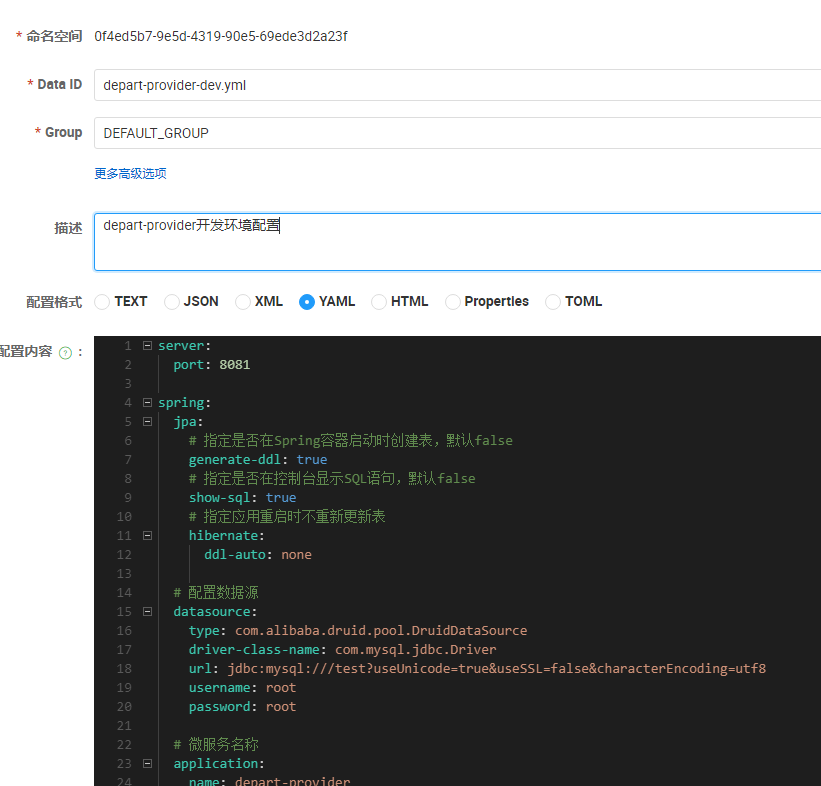
2、在配置中心对应的namespace下创建配置
nacos中,dataId不能随便写,完整格式如下:
1 | ${prefix}-${spring.profiles.active}.${file-extension} |
prefix 默认为 spring.application.name 的值,也可以通过配置项 spring.cloud.nacos.config.prefix 来配置。
spring.profiles.active 即为当前环境对应的 profile
file-extension为配置内容的数据格式。可以通过配置项 spring.cloud.nacos.config.file-extension 来配置。目前只支持 properties 和 yaml 类型。
3、添加依赖
1 | <dependency> |
4、不能使用原来的application.yml作为配置文件,而是新建一个bootstrap.yml作为配置文件
配置文件优先级(由高到低):
bootstrap.properties -> bootstrap.yml -> application.properties -> application.yml
1 | spring: |
不同环境下配置文件只需要修改namespace和active即可
注意:在SpringBoot 2.4.x的版本之后,默认禁用bootstrap,需要手动导入依赖:
1 | <dependency> |
5.3、配置动态刷新
上面的使用我们做到了远程存放,但是此时如果修改了配置,我们的程序是无法读取到 的,因此,我们需要开启配置的动态刷新功能
@RefreshScope
1 |
|
5.4、共享配置
当配置越来越多的时候,我们就发现有很多配置是重复的,这时候就可以考虑将公共配置文件 提取出来,然后实现共享
5.4.1、同一微服务不同环境之间共享配置
如果想在同一个微服务的不同环境之间实现配置共享,其实很简单。只需要提取一个以spring.application.name 命名的配置文件,然后将其所有环境的公共配置放在里面即可
5.4.2、不同微服务中共享配置
不同微服务之间实现配置共享的原理类似于文件引入,就是定义一个公共配置,然后在当前配置中引入。 1 在nacos中定义一个DataID为all-service.yaml(名字随意)的配置,用于所有微服务共享
1 | spring: |
6、流量治理 - sentinel
Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性
6.1、组成部分
sentinel 的使用可以分为两个部分:
1、核心库(Java 客户端):不依赖任何框架/库,能够运行于 Java 8 及以上的版本的运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
2、控制台(Dashboard):Dashboard 主要负责管理推送规则、监控、管理机器信息等。基于 Spring Boot 开发,打包后可以直接运行。
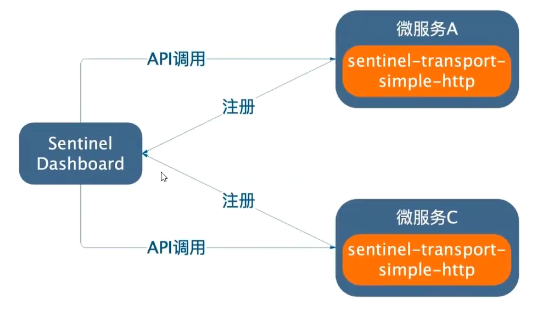
6.2、工作流程
在 Sentinel 里面,所有的资源都对应一个资源名称(resourceName),每次资源调用都会创建一个 Entry 对象。Entry可以通过对主流框架的适配自动创建,也可以通过注解的方式或调用 SphU API 显式创建。Entry 创建的时候,同时也会创建一系列功能插槽(slot chain),这些插槽有不同的职责,例如:
1、NodeSelectorSlot 负责收集资源的路径,并将这些资源的调用路径,以树状结构存储起来,用于根据调用路径来限流降级;
2、ClusterBuilderSlot 则用于存储资源的统计信息以及调用者信息,例如该资源的 RT, QPS, thread count 等等,这些信息将用作为多维度限流,降级的依据;
3、StatisticSlot 则用于记录、统计不同纬度的 runtime 指标监控信息;
4、FlowSlot 则用于根据预设的限流规则以及前面 slot 统计的状态,来进行流量控制;
5、AuthoritySlot 则根据配置的黑白名单和调用来源信息,来做黑白名单控制;
6、DegradeSlot 则通过统计信息以及预设的规则,来做熔断降级;
7、SystemSlot 则通过系统的状态,例如 load1 等,来控制总的入口流量;
6.3、基本使用
6.3.1、dashboard搭建
1、https://github.com/alibaba/sentinel/releases 下载jar包
2、执行命令启动
1 | java -jar sentinel-dashboard-1.8.7.jar --server.port=8888 |
3、访问localhost:8888 sentinel/sentinel
6.3.2、为服务打开0sentinel监控
1、添加依赖
1 | <dependency> |
2、添加配置
1 | spring: |
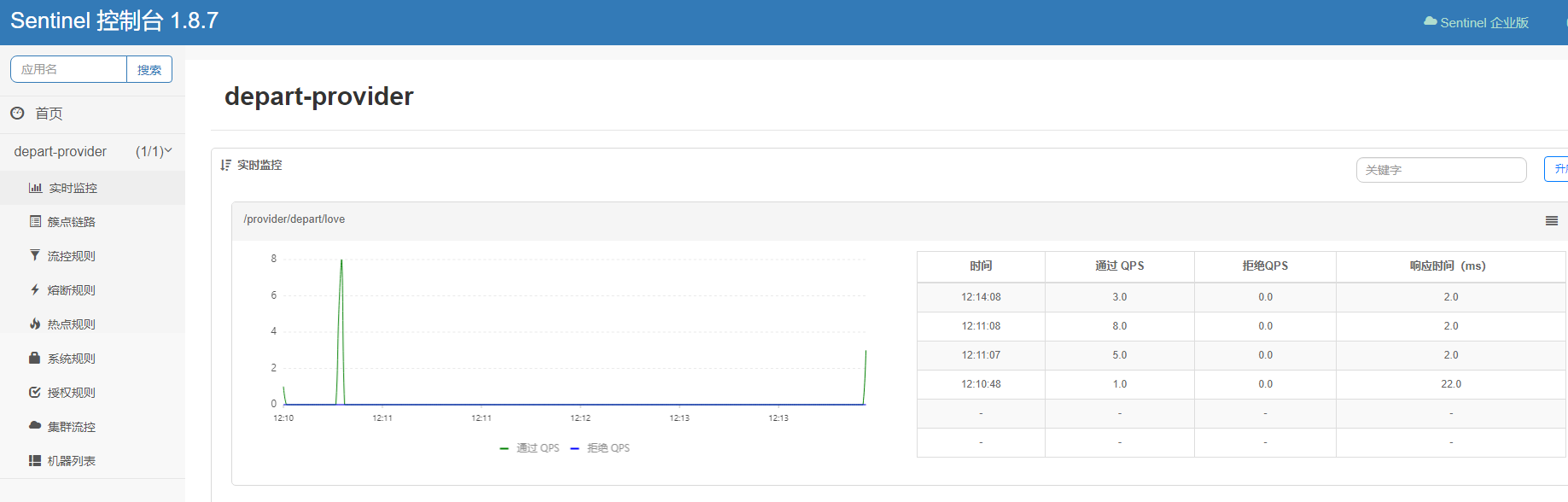
6.4、流控规则
6.4.1、流控规则属性
1、资源名: 唯一名称,默认请求路径,表示对该资源进行流控
2、针对来源: Sentinel可以针对调用者进行限流,填写微服务名,默认default(不区分来源)
3、阈值类型/单击阈值:
QPS:(每秒钟的请求数量):当调用该api的QPS达到阈值时,进行限流
线程数:当调用该线程数达到阈值的时候,进行限流
4、是否集群:不需要集群
5、流控模式:
直接: api达到限流条件时,直接限流
关联: 当关联的资源达到阈值时,就限流自己
链路: 只记录指定链路上的流量(指定资源从入口资源进来的流量,如果达到阈值,就进行限流)【api级别的针对来源】
6、流控效果:
快速失败: 直接失败,抛异常
Warm Up: 根据codeFactor(冷加载因子,默认3)的值,从阈值/codeFctor,经过预热时长,才达到设置的QPS阈值
排队等待: 匀速排队,让请求以匀速的速度通过,阈值类型必须设置为QPS,否则无效
6.4.2、自定义异常处理
@SentinelResource的属性
1、value:作用指定资源名称,必填
2、entryType:entry类型,标记流量的方向,指明是出口流量,还是入口流量;取值 IN/OUT ,默认是OUT。非必填
3、blockHandler:处理BlockException的函数名称,函数要求为必须是public返回类型与原方法一致。参数类型需要和原方法相匹配,并在最后加上BlockException类型的参数。默认需和原方法在同一个类中,如果希望使用其他类的函数,可配置blockHandlerClass,并指定blockHandlerClass里面的方法
4、blockHandlerClass:存放blockHandler的类。对应的处理函数必须static修饰,否则无法解析。函数要求为:必须是public,返回类型与原方法一致,参数类型需要和原方法相匹配,并在最后加上BlockException类型的参数
5、fallback:用于在抛出异常的时候提供fallback处理逻辑。fallback函数可以针对所有类型的异常(除了execptionsToIgnore 里面排除掉的异常类型)进行处理,函数要求为:返回类型与原方法一致参数类型需要和原方法相匹配,Sentinel 1.6版本之后,也可在方法最后加上Throwable类型的参数。默认需和原方法在同一个类中,若希望使用其他类的函数,可配置fallbackClass,并指定fallbackClass里面的方法
6、fallbackClass:存放fallback的类。对应的处理函数必须static修饰,否则无法解析,其他要求:同fallback。
7、defaultFallback:用于通用的 fallback 逻辑。默认fallback函数可以针对所有类型的异常(除了 exceptionsToIgnore 里面排除掉的异常类型)进行处理。若同时配置了 fallback 和 defaultFallback,以fallback为准。函数要求:
返回类型与原方法一致
方法参数列表为空,或者有一个Throwable类型的参数
默认需要和原方法在同一个类中,若希望使用其他类的函数,可配置fallbackclass,并指定fallbackClass里面的方法。
8、exceptionsToIgnore:指定排除掉哪些异常。排除的异常不会计入异常统计,也不会进入fallback逻辑,而是原样抛出
9、exceptionsToTrace:需要trace的异常
1 |
|
注意dashboard加流控规则的位置:
6.5、熔断处理
对于qps或并发这种外界因素导致的问题,通过流控可以解决问题。但对于故障(如网络故障)导致的阻塞,通过流控无法解决。这里考虑使用熔断中断服务,避免请求堆积造成更大的系统问题(雪崩)。
6.5.1、熔断规则策略
1、慢调用比例 (SLOW_REQUEST_RATIO):选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断
2、异常比例 (ERROR_RATIO):当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%
3、异常数 (ERROR_COUNT):当单位统计时长内的异常数目超过阈值之后会自动进行熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断
断路器工作流程:
一旦熔断,断路器的状态是Open(所有的请求都不能进来)
当熔断时长结束,断路器的状态是half-Open(可以允许一个请求进来)
如果接下来的请求正常,断路器的状态是close(资源就自恢复)
如果接下来的请求不正常,断路器的状态是open
6.5.2、熔断自定义异常处理
1、定义资源和处理逻辑
1 |
|
2、配置熔断规则
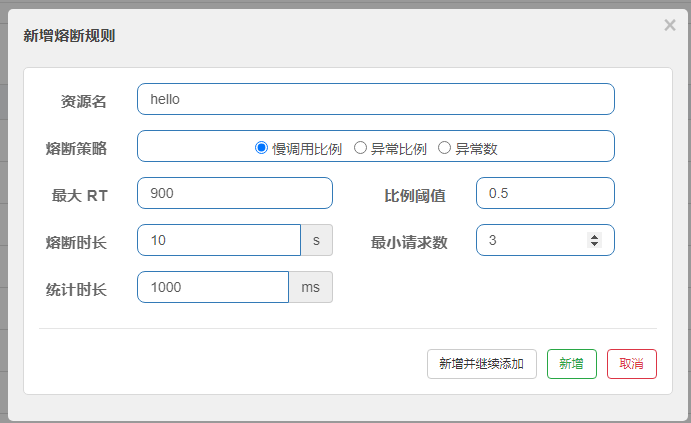
6.6、热点key限制
热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的 TopK数据,并对其访问进行限制。比如:用户 ID 为参数,针对一段时间内频繁访问的用户ID 进行限制热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。
6.6.1、基本使用
1、对应链路增加热点key限制
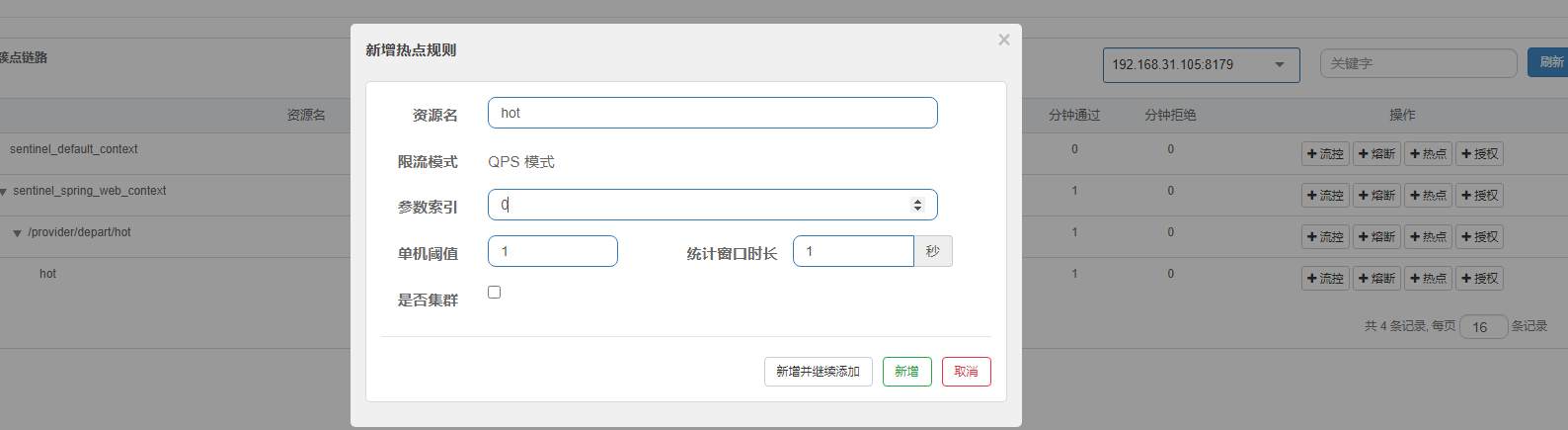
2、接口声明资源名称
1 |
|
3、请求时携带参数:http://localhost:9081/provider/depart/hot?id=1
6.7、权限规则
授权规则是对请求者的身份做一个判断。所有请求都要经过网关,网关去做身份的认证,查看访问权限,怎么sentinel还有身份判断呢?所有请求经过网关路由的微服务,这个时候网关当然可以对请求做身份的认证了。但是万一啊,你们公司里出了个内鬼,他把你们微服务的地址泄露给了外边的那些不怀好意的人。那就可以绕过网关直接访问微服务了。网关里做的安全校验失效所以呢,Sentinel的授权规则可以解决这个问题,因为它可以去验证你的请求是从哪来的。如果说你是从网关过来的,我让你走,如果你是从别的地方过来的拦截
6.7.1、基本使用
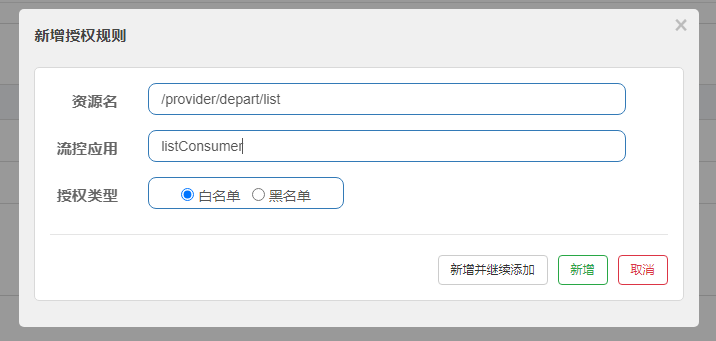
- 白名单:来源(origin)在白名单内的调用者允许访问
- 黑名单:来源(origin)在黑名单内的调用者不允许访问
1、新增授权规则
2、客户端添加来源解析器
1 |
|
特别注意:origin获取为空时要么直接报错(强权没问题),或者给默认值如上”xxxx”。否则授权失效
6.8、全局自定义异常处理
上面熔断,流控等自定义异常处理要指定rollback,还是比较麻烦,这里考虑使用全局自定义异常处理
1 | /* |
6.9、规则持久化
| 推送模式 | 说明 | 优点 | 缺点 | |
|---|---|---|---|---|
| 原始模式 | API将规则推送至客户端并直接更新到内存中 | 简单,无任何依赖 | 不保证一致性;规则保存在内存中,重启即消失。严重不建议用于生产环境 | |
| Pull模式 | 扩展写数据源(WritableDataSource),客户端主动向某个规则管理中心定期轮询拉取规则,这个规则中心可以是RDBMS、文件等 | 简单 | 不保证一致性;实时性不保证,拉取过于频繁也可能会有性能问题。 | |
| Push模式 | 扩展读数据源(ReadableDataSource),规则中心统一推送,客户端通过注册监听器的方式时刻监听变化,比如使用Nacos、Zookeeper等配置中心。这种方式有更好的实时性和一致性保证。生产环境下一般采用push模式的数据源。 | 规则持久化;一致性;快速 | 引入第三方依赖 |
6.9.1、pull模式
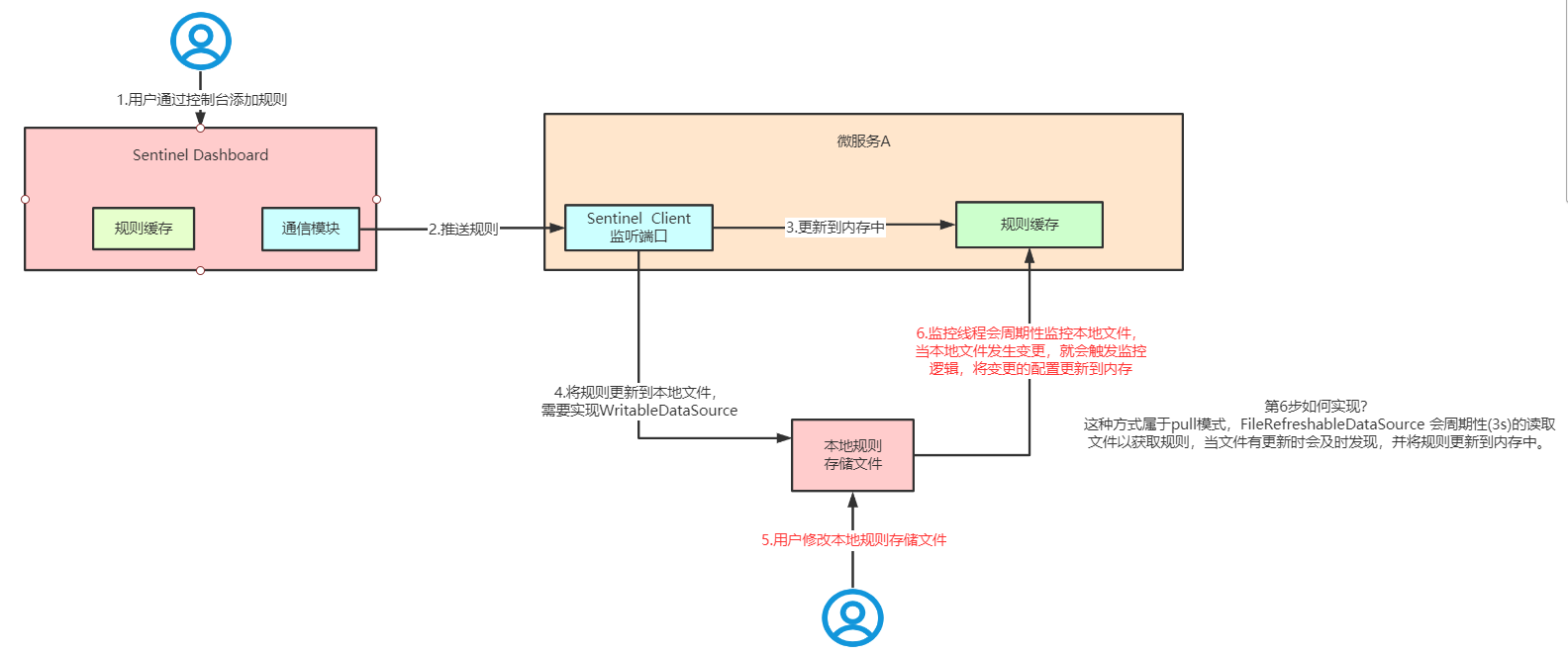
pull模式的数据源(如本地文件、RDBMS等)一般是可写入的。使用时需要在客户端注册数据源:将对应的读数据源注册至对应的 RuleManager,将写数据源注册至transport的WritableDataSourceRegistry中
1、引入依赖
1 | <dependency> |
2、实现InitFunc接口,在init中处理DataSource初始化逻辑,并利用spi机制实现加载
1 | public class FileDataSourceInit implements InitFunc { |
3、在META-INF/services目录下创建com.alibaba.csp.sentinel.init.InitFunc,内容如下:
1 | com.morris.user.config.FileDataSourceInit |
这样当在Dashboard中修改了配置后,Dashboard会调用客户端的接口修改客户端内存中的值,同时将配置写入文件FlowRule.json中,这样操作的话规则是实时生效的,如果是直接修改FlowRule.json的内容,这样需要等定时任务3秒后执行才能读到最新的规则
6.9.2、push模式
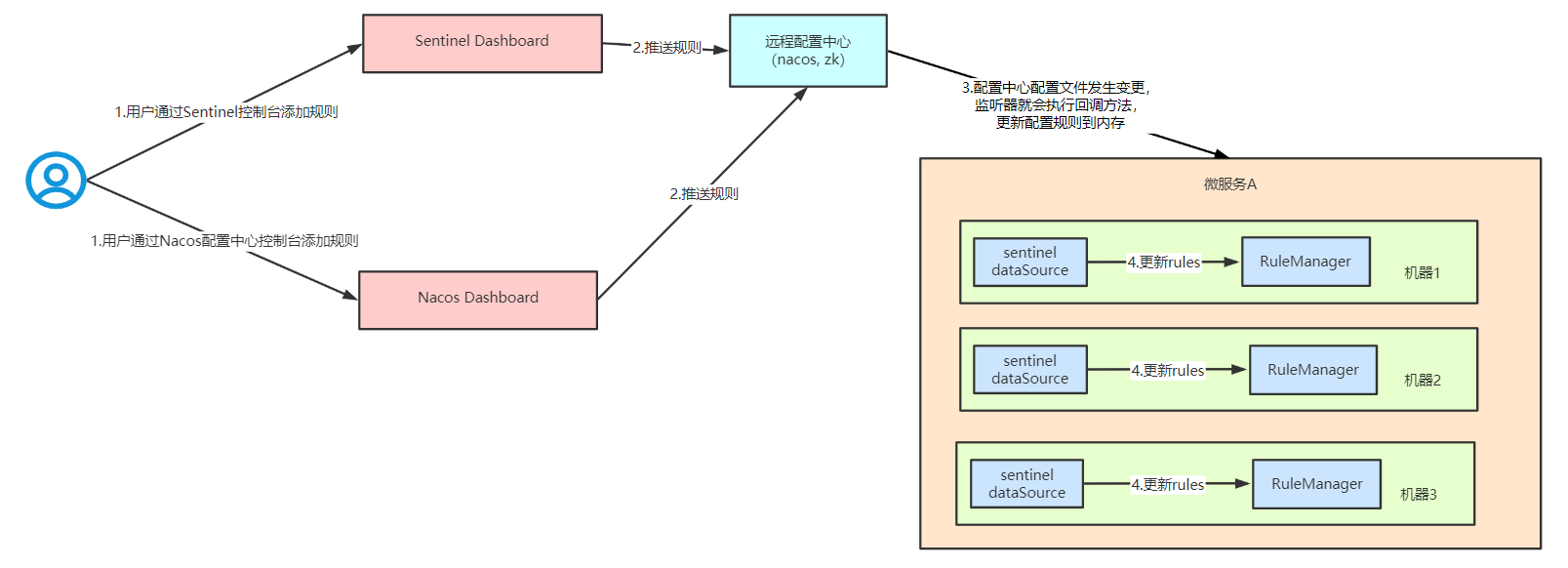
生产环境下一般更常用的是push模式的数据源。对于push模式的数据源,如远程配置中心(ZooKeeper, Nacos, Apollo等等),推送的操作不应由Sentinel客户端进行,而应该经控制台统一进行管理,直接进行推送,数据源仅负责获取配置中心推送的配置并更新到本地。因此推送规则正确做法应该是配置中心控制台/Sentinel控制台 → 配置中心 → Sentinel数据源 → Sentinel,而不是经Sentinel数据源推送至配置中心。这样的流程就非常清晰了
1、引入依赖
1 | <dependency> |
2、配置文件增加nacos数据源
1 | spring: |
3、最后在Nacos控制台新建一个user-service-flow的json配置,内容如下:
1 | [ |
这样直接在Nacos控制台修改规则就能实时生效了,缺点是直接在Sentinel Dashboard中修改规则配置,配置中心的配置不会发生变化
原理简述
1、控制台推送规则:将规则推送到Nacos或其他远程配置中心;
2、Sentinel客户端链接Nacos,获取规则配置;并监听Nacos配置变化,如发生变化,就更新本地缓存(从而让本地缓存总是和Nacos一致);
3、控制台监听Nacos配置变化,如发生变化就更新本地缓存(从而让控制台本地缓存总是和Nacos一致)
7、网关 - gateWay
在微服务架构中,一个系统会被拆分为很多个微服务。那么作为客户端要如何去调用这么多的微服务呢?如果没有网关的存在,我们只能在客户端记录每个微服务的地址,然后分别去调用。这样肯定是不合理的。
为解决上面的问题所以引入了网关的概念:所谓的API网关,就是指系统的统一入口,提供内部服务的路由中转,为客户端提供统一服务,一些与业务本身功能无关的公共逻辑可以在这里实现,诸如认证、鉴权、监控、路由转发等
你可能考虑到了nginx,使用nginx在配置文件中配置其实还是有硬编码的问题
7.1、gateWay核心概念
Route(路由):路由是构建网关的基础模块,它由ID,目标URI,包括一些列的断言和过滤器组成,如果断言为true则匹配该路由
Predicate(断言):参考的是Java8的java.util.function.Predicate,开发人员可以匹配HTTP请求中的所有内容(例如请求头或请求参数),请求与断言匹配则进行路由
Filter(过滤):指的是Spring框架中GateWayFilter的实例,使用过滤器,可以在请求被路由前或者之后对请求进行修改
1、客户端向spring cloud gateway发出请求,然后在gateway handler mapping中找到与请求相匹配的路由
2、将其发送到gateway web handler
3、Handler再通过指定过滤器链来将请求发送到我们实际的服务执行业务逻辑,然后返回
7.2、routes基本使用
1 | <dependencies> |
1、路由到指定URL
1 | spring: |
访问http://localhost:8040/** 跳转到https://www.baidu.com/**
2、路由到微服务
1 | spring: |
7.3、谓词断言工厂 - predicates
Route Predicate Factories(路由断言工厂)是Spring Cloud Gateway中的一种机制,用于定义路由规则中的断言条件。在Spring Cloud Gateway中,路由断言工厂允许基于HTTP请求的各种属性(例如路径、主机、请求方法、请求头等)来匹配和过滤路由。这些断言条件决定了请求是否会被路由到特定的目标服务
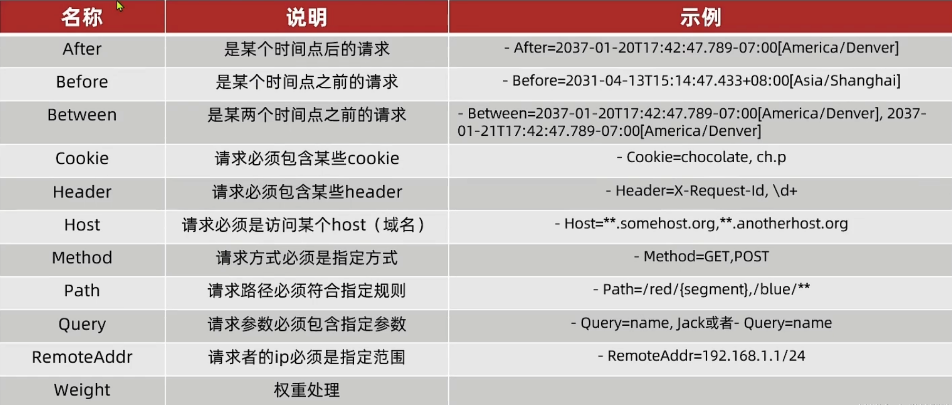
1、The After Route Predicate Factory
After路由谓词工厂采用一个日期时间参数(java ZonedDateTime)。此谓词匹配指定日期时间之后发生的请求。以下示例配置后路由谓词:
1 | spring: |
该配置匹配北京时间2024-06-01 08:42:47.789以后的任何请求。
2、The Before Route Predicate Factory
与1类似,Before谓词匹配指定日期时间之前的任何请求,示例:
1 | spring: |
该配置匹配北京时间2017-01-21 08:42:47.789以前的任何请求。
3、The Between Route Predicate Factory
Between路由谓词工厂有两个参数,与1)和2)相似,都是java ZonedDateTime对象。匹配两个时间之间的请求,参数2必须在参数1之后。以下示例配置了 Between 路由谓词:
1 | spring: |
该谓词匹配北京时间2017-01-21 08:42:47.789到2017-01-25 08:42:47.789之间的请求。
4、The Cookie Route Predicate Factory
Cookie路由谓词工厂采用两个参数:name和regexp(Java 正则表达式)。此谓词匹配cookie中具有给定名称(key)且其值(value)与正则表达式匹配的请求。以下示例配置 cookie 路由谓词工厂:
1 | spring: |
在这个例子中,chocolate表示cookie中key为chocolate,而ch.p表示value为ch+任意一个字符+p,例如chip,chap,ch1p等,但是不能匹配chp、chiip。
5、The Header Route Predicate Factory
Header路由谓词工厂采用两个参数:header和 regexp(Java 正则表达式)。与Cookie路由谓词工厂类似,只是将键值对从cookie中转移到了header中。以下示例配置Header路由谓词:
1 | spring: |
该谓词匹配header中有key为X-Request-Id、value匹配”\d+”即多个数字的请求。
6、The Host Route Predicate Factory
Host路由谓词工厂包含一个参数:主机名列表 patterns。该模式是 Ant 风格的模式,以.为分隔符。该谓词匹配Host与模式匹配的标头。以下示例配置主机路由谓词:
1 | spring: |
该谓词匹配例如www.somehost.org、image.somehost.org的请求,即任意开头+"somehost.org"或者"anotherhost.org"结尾的主机的请求。
7、The Method Route Predicate Factory
Method路由谓词工厂包含methods参数,该参数可能是一个或多个参数,如POST、GET等。以下示例配置method路由谓词:
1 | spring: |
该谓词匹配所有GET、POST请求。
8、The Path Route Predicate Factory
Path路由谓词工厂包含两个参数:一个 Spring 列表PathMatcher patterns和一个名为 matchTrailingSlash 的可选标志(默认为true)。以下示例配置路径路由谓词:
1 | spring: |
该谓词匹配/red或者/blue开头,且后面还有路径段的请求,如/red/apple,/red/apple/banana等,参数matchTrailingSlash=false表示忽略段尾的/,即将/red/apple和/red/apple/视为相同的请求,如果设置为true,则会根据规则区分这两种路径段。
9、The Query Route Predicate Factory
Query路由谓词工厂有两个参数:一个必需参数param和一个可选参数regexp( Java 正则表达式)。以下示例配置Query路由谓词:
1 | spring: |
该谓词匹配查询参数中包含green的请求,如www.example.org/get?green=1。
10、The RemoteAddr Route Predicate Factory
RemoteAddr路由谓词工厂的参数为一个列表(sources,最小大小为 1),它们是 CIDR 表示法(IPv4 或 IPv6)字符串,例如192.168.0.1/16(其中192.168.0.1是 IP 地址,16是子网掩码)。以下示例配置 RemoteAddr 路由谓词:
1 | spring: |
该谓词匹配请求来源的ip与子网掩码为192.168.1.1/24的请求。
11、The Weight Route Predicate Factory
Weight路由谓词工厂有两个参数:group和weight。权重分组计算。以下示例配置Weight路由谓词:
1 | spring: |
该配置表示大约80%的请求会发送到https://weighthigh1111.org,20%的请求会发送到https://weightlow2222.org。
7.4、过滤器 - filters
Gateway过滤器是Spring Cloud Gateway提供的一种机制,用于对进入网关的请求和返回进行处理和转换。它可以用于实现各种功能,如请求鉴权、请求转发、请求限流、请求重试等
7.4.1、内置过滤器
Spring官网给我们提供了很多很多中不同的过滤器,这里就简单列举几个
| 名称 | 说明 |
|---|---|
| AddRequestHeader | 给当前请求添加一个请求头 |
| RemoveRequestHeader | 移除请求中的一个请求头 |
| AddResponseHeader | 给响应结果添加一个响应头 |
| RemoveResponseHeader | 从响应结果中移除一个响应头 |
| RequestRateLimiter | 限制请求的流量 |
局部路由生效:可以将过滤器配置设置在yml文件中路由id的下一级,如下所示:
1 | spring: |
1 |
|
7.4.2、自定义过滤器
命名规范:过滤器工厂类名必须以GatewayFilterFactory为后缀
1 |
|
配置文件进行配置
1 | spring: |
7.4.3、全局过滤器
全局过滤器不和具体的路由关联,作用在所有路由上,不需要配置。通过全局过滤器可以实现对权限的统一校验,安全性校验等
实现方法:实现GlobalFilter接口
1 | // 全局打印请求路径 |