sharding-jdbc
1、基本概念
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成 ,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。分库分表分为分库和分表两部分,通常分为垂直分库、垂直分表、水平分库、水平分表
1.1、垂直分库
垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上。例如,将用户信息表和订单信息表分别存储在不同的数据库中,以减轻单个数据库的负载压力
1.2、水平分库
水平分库是将一个表的数据按照某个条件(例如,按照用户ID的范围或哈希值)分散存储在多个数据库中。每个数据库只存储部分数据。这样可以将数据库负载均衡,并提高查询性能。例如,将用户信息根据用户ID的哈希值分散存储在不同的数据库中
1.3、垂直分表
垂直分表是将一个表按照列的方式进行拆分,将不同的列存储在不同的表中。每个表负责存储特定的列数据。这样可以降低单个表的数据量和表的宽度,提高查询性能。例如,将用户表拆分为用户基本信息表和用户扩展信息表,分别存储基本信息和扩展信息
1.4、水平分表
水平分表是将一个表的数据按照某个条件(例如,按照时间范围或哈希值)分散存储在多个表中。每个表只存储部分数据。这样可以将表的数据量减小,提高查询性能。例如,将订单表按照订单创建时间的范围拆分为多个表,每个表存储一段时间内的订单数据。
1.5、分库分表带来的问题
- 事务一致性问题:由于分库分表把数据分布在不同库甚至不同服务器,不可避免会带来分布式事务问题
- 跨节点关联查询:但垂直分库后和不在一个数据库,甚至不在一台服务器,无法进行关联查询
- 跨节点分页,排序函数:跨节点多库进行查询时,limit分页、order by排序等问题,就变得比较复杂了
- 主键避重:在分库分表环境中,由于表中数据同时存在不同数据库中,主键值平时使用的自增长将无用武之地,某个分区数据库生成的ID无法保证全局唯一。因此需要单独设计全局主键,以避免跨库主键重复问题
2、sharding-jdbc相关概念
Sharding-JDBC是ShardingSphere的第一个产品,也是ShardingSphere的前身。 它定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架
1 | sharding: |
2.1、逻辑表
未参与分片(不带后缀等信息)的表,实际数据库中并不存在。如ims_sample_base
2.2、真实表
在分片的数据库中真实存在的物理表。如ims_sample_base_202308
2.3、数据节点
数据分片的最小单元。由数据源名称和数据表组成。如m1.ims_sample_base_202309
2.4、绑定表
指分片规则一致的主表和子表。例如: t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升
1 | SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11); |
2.5、五种分片策略
- none:不分片策略。对应NoneShardingStrategy ,不分片策略,SQL会被发给所有节点去执行,这个规则没有子项目可以配置。、
- inline:行表达式分片策略。对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持.只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: t_user_$->{u_id % 8}表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7
行表达式语法:
${begin..end}表示范围区间
${[unit1,unit2,unit3]}表示枚举值
行表达式中如果出现连续多个$ { expression }或$->{expression}表达式,整个表达式最终结果将根据每个子表达式结果进行笛卡尔组合
- standard 标准分片策略
对应StandardShardingStrategy。提供对SQL语句中的=,IN和BETWEENAND的分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。RangeShardingAlgorithm是可选的,用于处理BETWEEN AND分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEENAND将按照全库路由处理
- complex复合分片策略
对应ComplexShardingStrategy。复合分片策略提供对SQL语句中的=,IN和BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度
- hint分片策略
对应HintShardingStrategy。通过Hint而非SQL解析的方式分片的策略。对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。例:内部系统,按照员工登录主键分库,而数据库中并无此字段。SQL Hint支持通过JavaAPI和SQL注释(待实现)两种方式使用。
2.6、主键生成策略
shardingSphere提供灵活的配置分布式主键生成策略方式的主键生成策略,默认使用雪花算法 (snowflake) 生成64bit的长整型数据。当前提供了SNOWFLAKE、UUID 两种可用方式。
2.7、事务处理
有两种,一种是local,一种是XA(基于Atomikas来实现),还有一种未实现的柔性事务。其中如果不跨库,则选择local,否则则选择XA
3、基本原理
当Sharding-JDBC接受到一条SQL语句时,会陆续执行 SQL解析 => 查询优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并 ,最终返回执行结果
3.1、sql解析
SQL解析过程分为词法解析和语法解析。
词法解析器用于将SQL拆解为不可再分的原子符号,称为Token。并根据不同数据库方言所提供的字典,将其归类为关键字,表达式,字面量和操作符。 再使用语法解析器将SQL转换为抽象语法树。
例如,以下SQL:
1 | SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18 |
解析之后的为抽象语法树见下图:
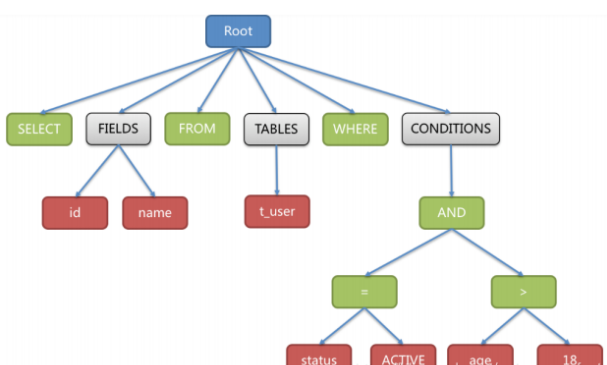
为了便于理解,抽象语法树中的关键字的Token用绿色表示,变量的Token用红色表示,灰色表示需要进一步拆分
3.2、sql路由
SQL路由就是把针对逻辑表的数据操作映射到对数据结点操作的过程。根据解析上下文匹配数据库和表的分片策略,并生成路由路径
- 对于携带分片键的sql
- 根据分片键操作符不同可以划分为单片路由(分片键的操作符是等号)、多片路由(分片键的操作符是IN)和范围路由(分片键的操作符是 BETWEEN)
- 根据分片键进行路由的效果可分为直接路由、标准路由、笛卡尔路由等标准路由是Sharding-Jdbc最为推荐使用的分片方式,它的适用范围是不包含关联查询或仅包含绑定表之间关联查询的SQL。 当分片运算符是等于号时,路由结果将落入单库(表),当分片运算符是BETWEEN或IN时,则路由结果不一定落入唯一的库(表),因此一条逻辑SQL最终可能被拆分为多条用于执行的真实SQL.笛卡尔路由是最复杂的情况,它无法根据绑定表的关系定位分片规则,因此非绑定表之间的关联查询需要拆解为笛卡尔积组合执行
- 不携带分片键的sql则采用广播路由
3.3、sql改写
工程师面向逻辑表书写的SQL,并不能够直接在真实的数据库中执行,SQL改写用于将逻辑SQL改写为在真实数据库中可以正确执行的SQL
1 | 如一个简单的例子,若逻辑SQL为: |
3.4、sql执行
Sharding-JDBC采用一套自动化的执行引擎,负责将路由和改写完成之后的真实SQL安全且高效发送到底层数据源执行。
它不是简单地将SQL通过JDBC直接发送至数据源执行;也并非直接将执行请求放入线程池去并发执行。它更关注平衡数据源连接创建以及内存占用所产生的消耗,以及最大限度地合理利用并发等问题
3.5、结果归并
将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端,称为结果归并。
Sharding-JDBC支持的结果归并从功能上可分为遍历、排序、分组、分页和聚合5种类型