java core
1、Java概述
1.1、java特点
- Java 语言是面向对象的(oop)
- Java 语言是健壮的。Java 的强类型机制、异常处理、垃圾的自动收集等是 Java 程序健壮性的重要保证
- Java 语言是跨平台性的。[即: 一个编译好的.class 文件可以在多个系统下运行,这种特性称为跨平台]
- java是一种半编译,半解释型语言。 . Java–>. class是由 Javac 编译,这个过程符合编译型语言的特点。而. class–>对应平台机器码 的这一过程 是由Java解释执行
1.2、访问修饰符

2、变量
2.1、java基本数据类型
java基本数据类型 - 四类八种
- 整型
byte 、short 、int 、long
- 浮点型
float 、 double
- 字符型
char
- 布尔型
boolean
| 数据类型名称 | 占用字节 | 范围 | 封装器类 |
|---|---|---|---|
| byte(字节型) | 1 | -(2^7) |
Byte |
| shot(短整型) | 2 | -(2^15) |
Short |
| int(整形) | 4 | -(2^31) |
Integer |
| long(长整型) | 8 | -(2^63)~2^63-1 | Long |
| float(浮点型) | 4 | -3.403E8~3.403E38 | Float |
| double(双精度浮点型) | 8 | -1.798E308~1.798E308 | Double |
| boolean(布尔型) | 1 | Boolean | |
| char(字符型) | 2 | Character |
注意:计算机的数值是用二进制补码表示的,二进制补码表示法中,最高位是用来表示符号的(0 表示正数,1 表示负数),其余位表示数值部分。所以,如果我们要表示最大的正数,我们需要把除了最高位之外的所有位都设为 1
2.2、基本数据类型转换
2.2.1、自动类型转换
当java程序在进行赋值或运算时,精度小的类型自动转换为精度大的数据类型,这个就是自动类型转换
精度由小到大排序:
byte short int long float double
1 | //自动类型转换细节 |
floatf=3.4;是否正确?
不正确。3.4是双精度数,将双精度型(double)赋值给浮点型(float)属于下转型(down-casting,也称为窄化)会造成精度损失,因此需要强制类型转换floatf=(float)3.4;或者写成floatf=3.4F;
2.2.2、强制类型转换
将容量大的数据类型转换为容量小的数据类型。使用时要加上强制转换符( ),但可能造成精度降低或溢出,格外要注意。
2.2.3、基本数据类型和String转换
- 基本数据类型转String类型
(1)将基本类型的值加 “” 即可
(2)String.valueOf(基本数据类型)
- String转基本数据类型
(1)基本类型包装类调用parseXX方法即可
3、运算符
3.1、算数运算符
算数运算符是对数值变量进行运算的,在java程序种使用非常多
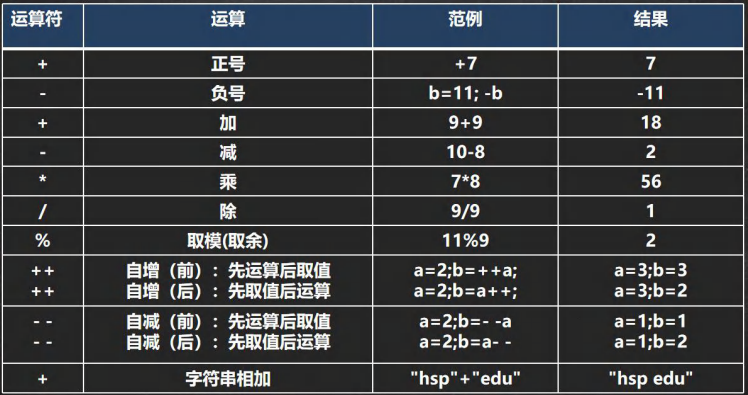
1 | // 题目1 |
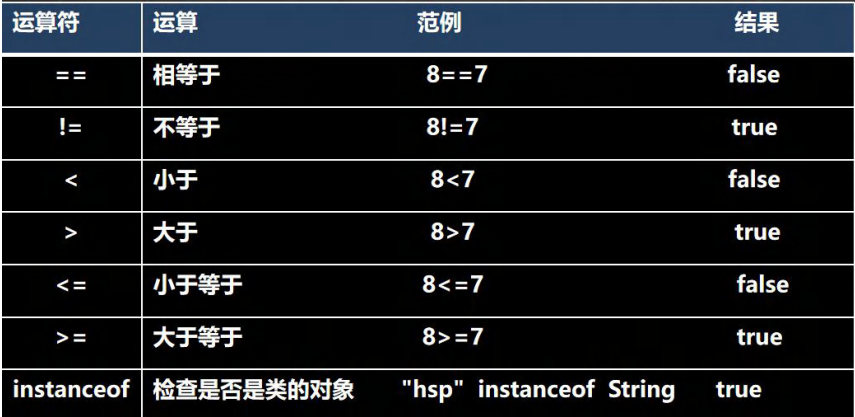
3.2、关系运算符
关系运算符的结果都是boolean型,也就是要么是true,要么是false
3.3、逻辑运算符
用于连接多个条件(多个关系表达式),最终的结果也是一个 boolean 值
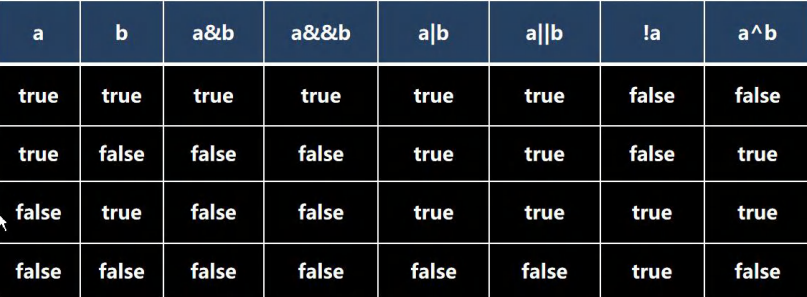
a^b: 叫逻辑异或 :当 a 和 b 不同时,则结果为 true, 否则为 false
&&短路与:如果第一个条件为 false,则第二个条件不会判断,最终结果为 false,效率高
& 逻辑与:不管第一个条件是否为 false,第二个条件都要判断,效率低
3.4、赋值运算符
基本赋值运算符 = ( int a = 10;)
复合赋值运算符 += ,-= ,*= , /= ,%= 等
3.5、三元运算符
条件表达式 ? 表达式 1: 表达式 2;
- 如果条件表达式为 true,运算后的结果是表达式 1;
- 如果条件表达式为 false,运算后的结果是表达式 2;
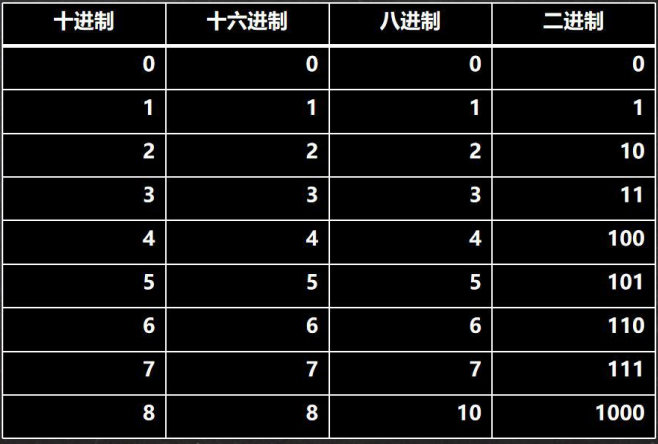
3.6、进制转换(为位运算准备)
对于整数,有四种表示方式:
二进制:0,1 ,满 2 进 1.以 0b 或 0B 开头。
十进制:0-9 ,满 10 进 1。
八进制:0-7 ,满 8 进 1. 以数字 0 开头表示。
十六进制:0-9 及 A(10)-F(15),满 16 进 1. 以 0x 或 0X 开头表示。此处的 A-F 不区分大小写

3.6.1、其它进制转十进制
- 二进制转十进制
规则:从最低位(右边)开始,将每个位上的数提取出来,乘以2的(位数-1)次方,然后求和
案例:将ob1011转成十进制数
1+2+8=11
- 八进制转十进制
规则:从最低位(右边)开始,将每个位上的数提取出来,乘以8的(位数-1)次方,然后求和
案例:0234转成十进制
4*1+3*8+2*64=156
- 十六进制转十进制
规则:从最低位(右边)开始,将每个位上的数提取出来,乘以16的(位数-1)次方,然后求和
案例:0x23A
10*1+3*16+2*512=570
3.6.2、十进制转其他进制
- 十进制转二进制
规则:将该数不断除以2.直到商为0为止,然后将每步余数倒过来,就是对应二进制
案例:34转为对应二进制 = 0B00100010
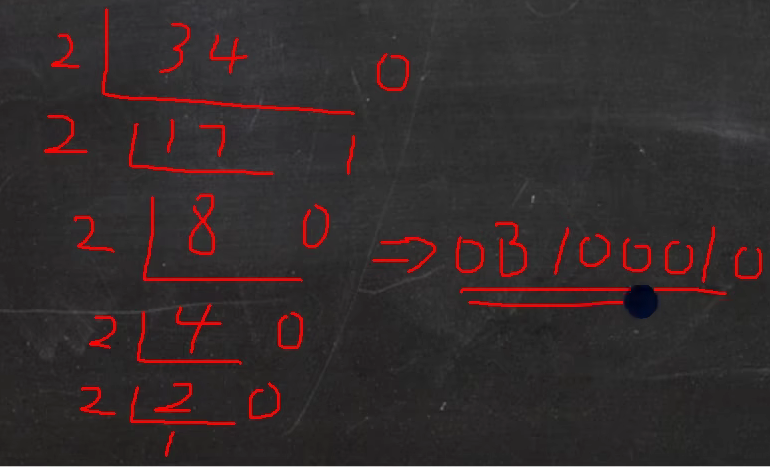
- 十进制转八进制
规则:将该数不断除以8.直到商为0为止,然后将每步余数倒过来,就是对应二进制
案例:131转为8进制
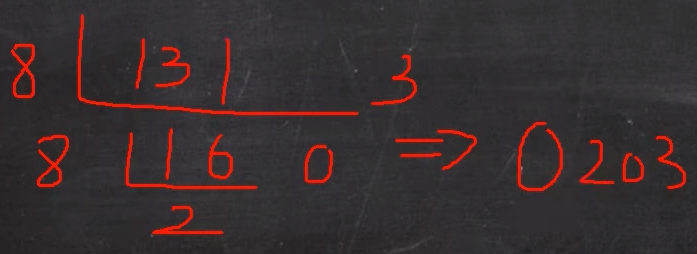
3.6.3、二进制转其它进制
- 二进制转八进制
规则:从低位开始,将二进制数每三位一组,转成对应的八进制
案例:0b11010101转成八进制
0325
- 二进制转十六进制
规则:从低位开始,将二进制数每四位一组,转成对应的十六进制数即可
案例:0b11010101转成十六进制
D5
3.6.4、其它进制转二进制
- 八进制转二进制
规则:将八进制数每1位。转成对应的一个3位的二进制数即可
案例:将0237转成二进制
0b10011111
- 十六进制转二进制
规则:将十六进制数每1位。转成对应的一个4位的二进制数即可
案例:请将0x23B转成二进制
0b001000111011
3.7、位运算符
3.7.1、原码反码补码
- 进制的最高位是符号位: 0表示正数1表示负数
- 正数的原码,反码,补码都一样
- 负数的反码=它的原码符号位不变,其它位取反.负数的补码=它的反码+1
- 0的反码,补码都是0
- 在计算机运算的时候,都是以补码的方式来运算的
- 补码的补码就是原码
为什么计算机通过补码进行运算?
通过使用补码,无需单独的符号位判断来执行加法和减法运算。计算机可以直接对补码进行位运算,而不需要额外的逻辑电路来处理符号位
3.7.2、位运算
java种有7个位运算 &(按位与),|(按位或),^(按位异或),~(按位取反),<<(左移),>>(带符号右移),>>>(无符号右移)
3.7.2.1、& (按位与)
两位全为1,结果为1,否则为0
1 | 10 (2) |
3.7.2.2、|(按位或)
两位一个为1,结果为1,否则为0
1 | 10 (2) |
3.7.2.3、 ^(按位异或)
两位一个为0,结果为1,否则为0
1 | 10 (2) |
3.7.2.4、~(按位取反)
0->1, 1->0
1 | ~2 |
3.7.2.5、>>(算数右移)
低位溢出,符号位不变,并用符号位补溢出的高位
1 | 1 >> 2 |
3.7.2.6、>> (算数左移)
符号位不变,低位补0
1 | 1 << 2 |
3.7.2.7、>>> (逻辑右移 或叫 无符号右移)
低位溢出,高位补0
1 | 8 >>> 2 |
4、面向对象
4.1、面向对象三大特征
4.1.1、封装
封装:尽量避免向外部暴露实现细节,只提供个别接口让使用方调用,降低耦合性。这样做的话,当自身的逻辑发生变化时,不会破坏使用方的逻辑,或是强制使用方修改自身的逻辑,而是只需要修改自身的代码就可以了
4.1.2、继承
继承:子类继承父类的特征和行为,使得子类对象(实例)具有父类的属性和方法。以降低代码编写的冗余度
4.1.3、多态
多态:父类的引用指向子类的对象。它的意义是可以让我们不用关心某个对象到底是什么具体类型,就可以使用该对象的某些方法,而这些方法通过一个抽象类或者接口来实现,多态就是提供父类调用子类代码的一个手段而已
java实现多态三个必要条件:继承,重写,向上转型(父类引用指向子类对象)
4.2、内部类
如果定义类在局部位置(方法中/代码块) :(1) 局部内部类 (2) 匿名内部类
如果定义在成员位置 (1) 成员内部类 (2) 静态内部类
4.2.1、局部内部类
局部内部类是定义在外部类的局部位置,比如方法中,并且有类名数据
说明:
- 可以直接访问外部类的所有成员,包括私有
- 不能添加访问修饰符,因为他就是一个局部变量,局部变量不能使用修饰符
- 作用域:仅在定义它的方法或代码块中
- 局部内部类访问外部类的成员:直接访问。外部类访问局部内部类的成员,创建对象再访问
1 | public class OuterClass { |
4.2.2、匿名内部类
匿名内部类是一种没有显式定义类名的内部类,定义在外部类的局部位置,比如方法中,它通常用于创建实现某个接口或继承某个类的匿名对象
说明:
- 匿名内部类运行类型:外部类名称$1
- 基于接口的匿名内部类
1 | interface IA{ |
- 基于类的匿名内部类
1 | class Father { |
4.2.3、成员内部类
成员内部类是定义在外部类的成员位置,并且没有static修饰
说明:
- 可以直接访问外部类的所有成员,包括私有的
- 可以添加任何修饰符,因为它的地位就是一个成员
1 | public static void main(String[] args) { |
4.2.4、静态内部类
成员内部类是定义再外部类的成员位置,有static修饰
1 | public static void main(String[] args) { |
4.3、重载和重写
重载发生在一个类中,同名的方法如果有不同的参数列表(参数类型不同、参数个数不同或者二者都不同)则视为重载
重写,子类重写父类方法,返回值(JDK7以后,被重写的方法返回值类型可以不同,但是必须是父类返回值的派生类)和形参都不能改变
不能根据返回类型来区分重载
float max(int a, int b);
int max(int a, int b);
上面两个方法名称和参数都一致,如果在同一个类中,别的地方调用的时候都是max(1,2),不能区分出想调用哪个方法
4.4、抽象类和接口
1、接口的设计目的,是对类的行为进行约束。也就是提供一种机制,可以强制要求不同的类具有相同的行为。它只约束了行为的有无,但不对如何实现行为进行限制
2、而抽象类的设计目的,是代码复用。当不同的类具有某些相同的行为。可以在抽象类中实现这种行为。这样它所有的子类就无需重复实现。达到代码复用的目的
4.5、Object类常用方法
- hashcode():将对象的16进制地址值,经过hash算法换算成整值
- toString():返回该对象的字符串对象
- equals():比较两个对象的地址值是否相同
- clone():实现对象的浅拷贝
- getclass():获取该对象的字节码文件(该对象运行时的类)Class
- wait()notify()notifyAll():wait()让当前线程进入等待状态。直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法
void notify():唤醒一个正在等待该对象的线程。
void notifyAll():唤醒所有正在等待该对象的线程
- equals()没有被重写的情况下等同于 ==
Object的equals()方法源码:
public boolean equals(Object obj) {
return (this == obj);
}
这用情况= =和equals()都是引用比较- string重写了Object的equals()方法这种情况equals()是值比较
4.6、深拷贝和浅拷贝
浅拷贝:基本数据类型复制值,引用数据类型复制地址,即拷贝出来的对象与被拷贝出来的对象中的引用的对象是同一个(java默认):clone方法
深拷贝:基本数据类型复制值,引用数据类型,创建一个新的对象,并复制其内容
1 | // 使用对象序列化来实现克隆 |
4.7、面向对象和面向过程的理解
是两种不同的处理问题的角度。面向过程更注重事情的每一个步骤及顺序,面向对象更注重事情有哪些参与者(对象)、及各自需要做什么
比如:洗衣机洗衣服
面向过程:会将任务拆解成一系列的步骤(函数),1、打开洗衣机 2、放衣服3、放洗衣粉4、清洗 5、烘干
面向对象:会拆出人和洗衣机两个对象:人:打开洗衣机,放衣服,放洗衣粉 洗衣机:清洗,烘干
从以上例子能看出,面向过程比较简单直接,而面向对象更易于复用、扩展和维护
4.8、sleep()和wait()区别
- 所属的类型不同
- wait()是Object类的实例方法,调用该方法的线程将进入WTING状态。
- sleep()是Thread类的静态方法,调用该方法的线程将进入TIMED_WTING状态
- 对锁的依赖不同
- wait()依赖于synchronized锁,通过监视器进行调用,调用后线程会释放锁。
- sleep()不依赖于任何锁,所以在调用后它也不会释放锁。
- 返回的条件不同
- 调用wait()进入等待状态的线程,需要由notify()/notifyAll()唤醒,从而返回。
- 调用sleep()进入超时等待的线程,需要在超时时间到达后自动返回。
5、枚举
5.1、实现方式
枚举是一组常量的集合。 可以这样理解:枚举属于一种特殊的类,里面只包含一组有限的特定的对象
5.1.1、 自定义类实现枚举
- 不需提供set方法,因为枚举对象值通常为只读
- 对枚举对象/属性使用final+static共同修饰,实现底层优化
- 枚举 对象名通常使用全部大写,常量的命名规范
1 | class Season {//类 |
5.1.2、enum关键字实现枚举
- 当我们使用 enum 关键字开发一个枚举类时,默认会继承 Enum 类, 这样我们就可以使用 Enum 类相关的方法
- 如果使用无参构造器 创建 枚举对象,则实参列表和小括号都可以省略
- 当有多个枚举对象时,使用,间隔,最后有一个分号结尾
- 枚举对象必须放在枚举类的行首
1 | public class Enumeration03 { |
6、注解
注解(Annotation)也被称为元数据(Metadata),用于修饰解释 包、类、方法、属性、构造器、局部变量等数据信息 。和注释一样,注解不影响程序逻辑,但注解可以被编译或运行,相当于嵌入在代码中的补充信息
6.1、基本注解介绍
使用 Annotation 时要在其前面增加 @ 符号, 并把该 Annotation 当成一个修饰符使用。用于修饰它支持的程序元素
三个基本的 Annotation:
- @Override: 限定某个方法,是重写父类方法, 该注解只能用于方法
- @Deprecated: 用于表示某个程序元素(类, 方法等)已过时
- @SuppressWarnings: 抑制编译器警告(当不希望看到某些警告使用该注解,都不想看到使用all)
6.2、自定义注解
修饰符:访问修饰符必须为public,不写默认为pubic;
关键字:关键字为@interface;
注解名称: 注解名称为自定义注解的名称,使用时还会用到;
注解类型元素:注解属性 ( 接口方法 ) 返回值类型要求 ,可以使用default来进行赋默认值;
1 | public Info { |
6.3、元注解
所谓元注解,其主要作用就是负责注解其他注解,为其他注解提供了相关的解释说明。
Java中存在五个元注解,分别是 @Target、@Retention、@Documented、@Inherited、@Repeatable
- Target:描述了注解修饰的对象范围,取值在java.lang.annotation.ElementType定义,常用包括:
METHOD:用于描述方法
PACKAGE:用于描述包
PARAMETER:用于描述方法变量
TYPE:用于描述类、接口或enum类型
- Retention:表述注解保留时间的长短,取值在java.lang.annotation.RetentionPolicy中,取值:
SOURCE:在源文件中有效,编译过程中会被忽略
CLASS:随源文件一起编译在class文件中,运行时忽略
RUNTIME:在运行时有效(只有定义为RetentionPolicy.RUNTIME时,我们才能通过注解反射获取注解)
Document:表明这个注解应该被 javadoc文档注释工具记录,正常情况下javadoc中不包含注解的,@Documented属于标志注解
Inherited:被该注解注解的元注解注解某个类时,子类继承该注解
@Repeatable 是 Java 8 引入的一个注解,用于在同一个元素上多次使用相同的注解。通过使用 @Repeatable 注解,可以使得某个注解可以重复应用于同一目标上,而无需使用容器注解或数组
1 |
|
6.4、案例-自定义注解实现日志功能
- 定义一个注解
1 |
|
- 创建切面类,使用 @Before 注解和 @AfterReturning 注解分别标记了在方法执行前和方法执行后执行的通知方法
1 |
|
- 在需要进行日志记录的方法上添加 @Loggable 注解即可
1 | public class MyClass { |
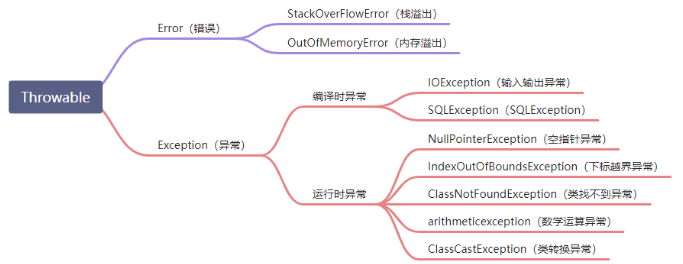
7、异常
7.1、Error(错误)
程序本身不能处理的异常,只能靠外接干预 (常见的如内存溢出,jvm虚拟机自身的非正常运行等)
7.2、Exception(异常)
是程序正常运行中,可以预料的意外情况。比如数据库连接中断,空指针,数组下标越界。异常出现可以导致程序非正常终止
(1)编译时异常
又叫可检查异常,Java语言强制要求捕获和处理所有非运行时异常。通过行为规范,强化程序的健壮性和安全性
(2)运行时异常
又叫不检查异常RuntimeException,这些异常一般是由程序逻辑错误引起的,即语义错
8、常用类
8.1、日期类
8.1.1、第一代日期类Date(JDK1.0)
- Date:精确到毫秒,代表特定瞬间
- SimpleDateFormat:格式化(日期-文本)和解析日期(文本-日期)的类
1 |
|
8.1.2、第二代日期类Calendar(JDK1.1)
Calendar它是一种抽象类,相比Date它在操作日历的时候提供了一些方法来操作日历字段
1 | // Calendar 是一个抽象类, 并且构造器是 private,可以通过 getInstance() 来获取实例 |
8.1.3、第三代日期类LocalDate(JDK8)
- Calendar日期类存在的问题?
(1)可变性,像日期和时间这样的类应该是不可变的
(2)格式化,格式化只对Date有用,Calendar只能自己拼装
(3)不是线程安全的;不能处理闰秒(每隔两天,多出一秒)等
- 基本概念
LocalDate:日期(年月日)
LocalTime:包含时间(时分秒)
LocalDateTime:包含日期+时间(年月日时分秒)
1 | //1. 使用 now() 返回表示当前日期时间的 对象 |
8.2、容器
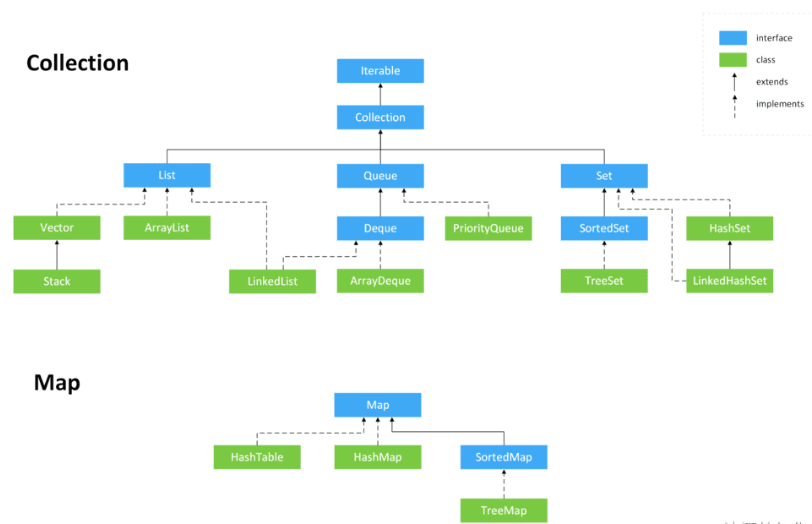
| 名称 | 底层 | 线程安全性 | 扩容机制 | 备注 |
|---|---|---|---|---|
| ArrayList | 数组 | 线程不安全 | 首次创建长度为10,扩为1.5倍 | 查找快,增删慢 |
| Vector | 数组 | 线程安全 | 首次创建长度为10,扩为1.5倍 | 查找快,增删慢 |
| LinkedList | 双向链表 | 线程不安全 | 不主动扩容 | 增删快,查找慢 |
| HashSet | HashMap | 线程不安全 | 可以存null | |
| LinkedHashSet | LinkedHashMap | 线程不安全 | 可以存null | |
| TreeSet | TreeMap | 线程不安全 | 不允许存null | |
| HashMap | 数组+链表(jdk7) 数组+链表+红黑树 (jdk8) | 线程不安全 | 首次创建长度16,扩容2倍,负载因子0.75 | 可以存nul |
| LinkedHashMap | 同hashmap | 线程不安全 | 不主动扩容 | 可以存null |
| HashTable | 数组+链表 | 线程安全 | 首次创建时长度为11,扩容为2n+1 | 不能为null |
| TreeMap | 红黑树 | 线程不安全 | TreeMap由红黑树实现,容量方面没有限制 | 不能为null 可以实现自然排序和定制排序 |
8.2.1、hashmap原理
hashmap数据结构是数组+链表+红黑树,HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对
两个重要的方法put() get()
(1).put方法:调用key的hash方法得hash值,再与(数组长度-1)做与(&)运算,到这个元素在数组中的位置(即下标)如果该位置已经存在其它元素,那么在同一个位子上的元素将以链表的形式存放,通过equals方法依次比较链表中的key,相同则替换。不同则添加到表尾(1.8之前添加到表头)。
(2).get方法:调用key的hash方法得到这个元素在数组中的位置(即下标),然后通过key的equals方法在对应位置的链表中找到需要的元素。
(需要注意Jdk 1.8中对HashMap的实现做了优化,当链表长度大于8且数组长度超过64并之后,该链表会转为红黑树来提高查询效率,从原来的O(n)到O(logn))
如果数组长度不足64,优先会进行扩容
8.2.2、自然排序和定制排序
自然排序:实现Comparable接口,实现compareTo方法
典型实现:String,Integer,Date等
定制排序:当元素对象没有实现comparable接口,又不方便修改,可以考虑使用定制排序,直接在调用方排序
1 | Collections.sort(arrayList, new Comparator<Integer>() { |
8.3、String
不可变性的理解:
1 | String s = "abc"; //(1) |
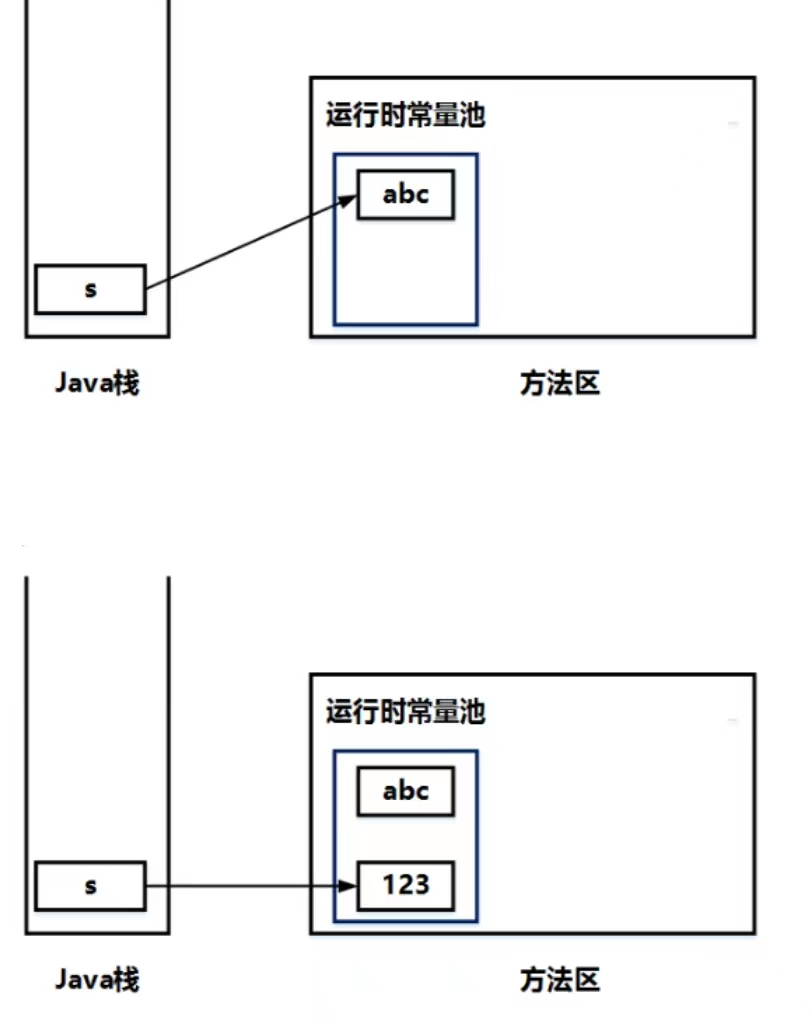
s只是一个String对象的引用,并不是String对象本身。
当执行(1)处这行代码之后,会先在方法区的运行时常量池创建一个String对象”abc”,然后在Java栈中创建一个String对象的引用s,并让s指向”abc”
当执行完(2)处这行代码之后,会在方法区的运行时常量池创建一个新的String对象”123”,然后让引用s重新指向这个新的对象,而原来的对象”abc”还在内存中,并没有改变
为什么这样设计?
(1)、字符串常量池中的对象可能被很多对象引用,如果一个修改会导致所有对象的内容都变
(2)、hashmap中key的hash方法只会调用一次然后缓存起来,如果key可变会导致缓存的结果和真实的计算结果不一致
8.4、ThreadLocal
8.4.1、ThreadLocal原理
ThreadLocal即线程变量,它用于共享变量在多线程中的隔绝,即每个线程都有一个该变量的副本彼此互不影响也就不需要同步机制了
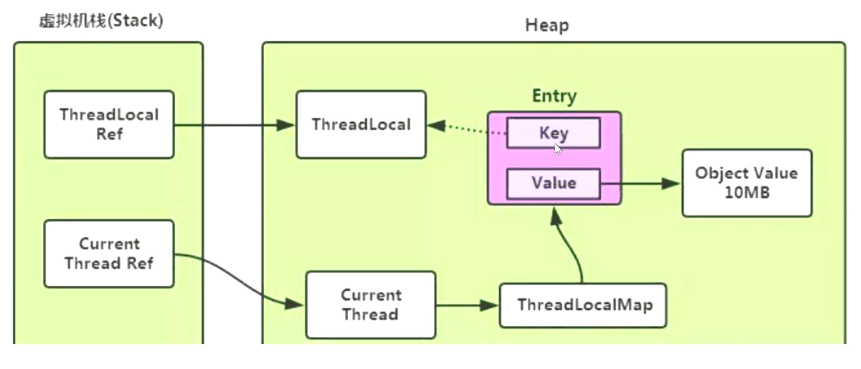
每个Thread对象都有一个ThreadLocalMap,当创建一个ThreadLocal的时候,就会将该ThreadLocal对象添加到该Map中,其中键就是ThreadLocal,值可以是任意类型。这样就实现了ThreadLocal在一个线程中是共享的,在不同线程之间是隔离的
8.4.2、ThreadLocal存在的问题 - 内存泄漏
- 弱引用
正是因为有引用,对象才会在内存中存在。当对象的引用数量归零后,垃圾回收程序会把对象销毁。弱引用不会增加对象的引用数量。 引用的目标对象称为所指对象(referent)。 因此我们说,弱引用不会妨碍所指对象被当作垃圾回收。
- ThreadLocalMap的key使用弱引用原因
假如使用强引用,当ThreadLocal不再使用需要回收时,发现某个线程中ThreadLocalMap存在该ThreadLocal的强引用,无法回收,造成内存泄漏。因此,使用弱引用可以防止长期存在的线程(通常使用了线程池)导致ThreadLocal无法回收造成内存泄漏。
- 通常说的ThreadLocal泄露是什么原因
我们注意到Entry对象中,虽然Key(ThreadLocal)是通过弱引用引入的,但是value即变量值本身是通过强引用引入。
这就导致,假如不作任何处理,由于ThreadLocalMap和线程的生命周期是一致的,当线程资源长期不释放,即使ThreadLocal本身由于弱引用机制已经回收掉了,但value还是驻留在线程的ThreadLocalMap的Entry中。即存在key为null,但value却有值的无效Entry。导致内存泄漏。
- 怎么避免内存泄露?
1.Threadlocal自身做了一些处理,在每次调用ThreadLocal的get、set、remove方法时都会执行一个方法,该方法检测整个Entry[]表中对key为null的Entry一并擦除,重新调整索引
2.程序员自身,在代码逻辑中使用完ThreadLocal,都要调用remove方法,及时清理
8.4.3、ThreadLocal使用场景
ThreadLocal最常见使用场景可用来解决数据库连接、Session用户管理等。
- 数据库连接
频繁创建和关闭Connection是一件非常耗费资源的操作,因此需要创建数据库连接池。ThreadLocal能够实现当前线程的操作都是用同一个Connection,保证了事务
1 | private static ThreadLocal<Connection> connectionHolder = new ThreadLocal<Connection>() { |
session用户管理
1
2
3
4
5
6
7
8
9
10
11
12
13private static final ThreadLocal threadSession = new ThreadLocal();
public static Session getSession() throws InfrastructureException {
Session s = (Session) threadSession.get();
try {
if (s == null) {
s = getSessionFactory().openSession();
threadSession.set(s);
}
} catch (HibernateException ex) {
throw new InfrastructureException(ex);
}
return s;
}避免一些参数的传递
比如我们在底层方法用到某个参数时,不一定要从顶层方法一层层传下去,可以存到ThreadLocal,使用的时候直接去取
9、泛型
9.1、基本概念
(1)泛型:Java在jdk5引入了泛型,在没有泛型之前,每次从集合中读取的对象都必须进行类型转换,如果在插入对象时,类型出错,那么在运行时转换处理的阶段就会报错。在提出泛型之后就可以明确的指定集合接受哪些对象类型,编译器就能知晓并且自动为插入的代码进行泛化,在编译阶段告知是否插入类型错误的对象,程序会变得更加安全清晰。
(2)泛型擦除:Java泛型是伪泛型,因为Java代码在编译阶段,所有的泛型信息会被擦除,Java的泛型基本上都是在编辑器这个层次上实现的,在生成的字节码文件中是不包含泛型信息的,使用泛型的时候加上的类型,在编译阶段会被擦除掉,这个过程称为泛型擦除。
为什么使用泛型?
(1)保证类型安全:可以确保在编译时期检测到类型不匹配的错误,避免在运行时出现类型转换错误
(2)消除强制转换:消除源代码中的许多强制类型转换,这使得代码更加可读,并且减少了出错机会
9.2、泛型使用方式
泛型有三种使用方式,分别为:泛型类、泛型接口和泛型方法。
T是泛型中的类型参数声明,它表示一个占位符,通常用大写字母表示(例如 T、E、K、V 等),但实际上它只是一个占位符,可以根据需要自定义
T:任意类型 type
E:集合中元素的类型 element
K:key-value形式 key
V:key-value形式 value
1 | // 泛型类 |
9.3、泛型通配符
泛型通配符是一种特殊的类型参数,用于在使用泛型时表示未知类型或限制类型范围
1 | // 1:表示类型参数可以是任何类型 |
9.4、实现原理
原码:
1 | public class Caculate<T> { |
编译后的代码:
1 | public class Caculate{ |
java的泛型称为伪泛型,因为Java的泛型只是编译期的泛型,一旦编译成字节码,泛型就被擦除了,即在Java中使用泛型,我们无法在运行期知道泛型的类型,一旦编译成字节码,泛型将被取代为Object。
在不使用泛型时,我们需要将Object手动转型成特定类型,而在使用泛型后,我们不需要自己转型,但实际上我们get到的对象仍然是Object类型的,只不过编译器会自动帮我们加入这个转型动作
10、IO
10.1、概述
10.1.1、简介
I(Input)O(Output):中文翻译为输入输出,我们知道计算机的数据不管是软件、视频、音乐、游戏等最终都是存储在硬盘中的,当我们打开后,由CPU将硬盘中的数据读取到内存中来运行。这样一个过程就产生了I/O(输入/输出)
输入:硬盘 -> 内存
输出:内存 -> 硬盘
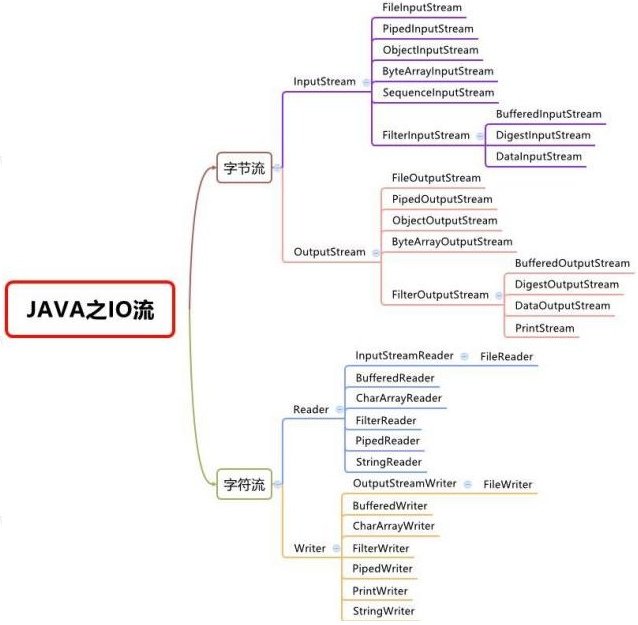
10.1.2、IO流的分类
按照操作数据单位不同分为:字节流(8bit)二进制文件,字符流(按字符)文本文件
按数据流的流向不同分为:输入流,输出流

java的IO流共涉及40多个类,都是从如上4个抽象基类派生
10.2、字节流
10.2.1、字节输出流
OutputStream是所有字节输出的顶层父类,该父类提供如下公共方法:
10.2.1.1、FileOutputStream
FileOutputStream是OutputStream中一个常用的子类,他可以关联一个文件,用于将数据写出到文件
构造方法:
public FileOutputStream(File file):创建文件输出流以写入由指定的 File对象表示的文件。
public FileOutputStream(String name): 创建文件输出流以指定的名称写入文件。
1 | public class IOTest { |
需要注意的是,在UTF-8编码下,一个中文占用3个字节,GBK编码下一个中文占用2个字节,因此在使用字节流来精确操作字符数据时将会变得非常麻烦
10.2.2、字节输入流
10.2.2.1、FileInputStream
java.io.FileInputStream类是文件输入流,从文件中读取字节
构造方法:
FileInputStream(File file): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的 File对象 file命名。
FileInputStream(String name): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的路径名 name命名。
1 | public class IOTest { |
10.3、字符流
计算机都是按照字节进行存储的,我们之前学习过编码表,通过编码表可以将字节转换为对应的字符,但是世界上有非常多的编码表,不同的编码表规定的单个字符所占用的字节可能都不一样,例如在GBK编码表中一个中文占2个字节,UTF8编码表则占3个字节;且一个中文字符都是由多个字节组成的,为此我们不能再基于字节的操作单位来操作文本文件了,因为这样太过麻烦,我们希望基于字符来操作文件,一次操作读取一个“字符”而不是一个“字节”,这样在操作文本文件时非常便捷
10.3.1、字符输出流
10.3.1.1、FileWriter类
java.io.FileWriter类是写出字符到文件的便利类。构造时使用系统默认的字符编码和默认字节缓冲区
1 | public class Demo03_写出字符数组 { |
10.3.2、字符输入流
10.3.2.1、FileReader类
java.io.FileReader类是读取字符文件的便利类。构造时使用系统默认的字符编码和默认字节缓冲区
Windows系统的中文编码默认是GBK编码表。idea中默认是UTF-8
1 | public class IoTest { |
11、反射
11.1、概述
11.1.1、基本概念
Java反射是指在运行时动态地获取类的信息并操作类或对象的能力。它提供了一组API,使得可以在运行时检查类、接口、字段和方法,并且可以在运行时实例化对象、调用方法、获取和设置字段的值
11.1.2、好处
- 运行时类信息:反射允许在运行时获取类的信息,包括类的名称、字段、方法、注解等。这使得可以动态地了解和操作类的结构,从而实现更加灵活和通用的代码设计。
- 动态创建对象:通过反射可以在运行时动态地实例化对象,而不需要在编译时明确知道类的类型。这对于根据配置文件或用户输入来创建对象非常有用,可以实现更大程度的灵活性和可配置性。
- 动态调用方法:反射可以在运行时动态地调用类的方法,包括公共方法、私有方法和静态方法。这对于实现插件机制、扩展性和动态逻辑非常有用,可以根据运行时条件来调用不同的方法。
- 访问私有成员:反射可以绕过访问权限限制,访问类的私有成员。这对于测试、调试和特定场景下的操作非常有用,但也需要小心使用,以遵循封装原则。
- 序列化和反序列化:反射在序列化和反序列化过程中起着重要的作用。通过反射可以分析对象的结构,并将其转换为字节流或从字节流中重建对象
11.2、 获取Class对象的方式
- Class.forName(“全类名”):将字节码文件加载进内存,返回Class对象。多用于配置文件,将类名定义在配置文件中。读取文件,加载类
- 类名.class:通过类名的属性class获取,多用于参数的传递
- 对象.getClass():getClass()方法在Object类中定义着
同一个字节码文件(*.class)在一次程序运行过程中,只会被加载一次,不论通过哪一种方式获取的Class对象都是同一个。
11.3、Class对象功能
- 获取成员变量
1 | Field[] getFields() :获取所有public修饰的成员变量 |
- 获取构造方法
1 | Constructor<?>[] getConstructors() 返回public修饰的构造方法 |
- 获取成员方法
1 | Method[] getMethods() |
- 获取全类名
1 | String getName() |
11.4、Field 成员变量
1 | 1. 设置值 |
11.5、Constructor 构造方法
1 | T newInstance(Object... initargs) |
11.6、Method 方法对象
1 | 1. 执行方法: |
12、异常
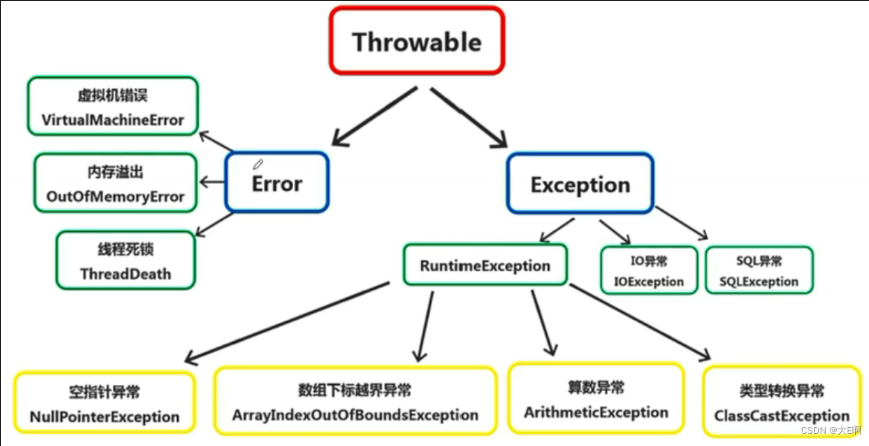
Error:错误,无法被处理的
Exception:异常,能够被程序本身处理的,可以通过try…catch语句捕捉异常,或者是throws抛出异常。分为运行时异常和非运行时异常
- 运行时异常:就是RuntimeException,编译时不会检查出错误的。一般是由于逻辑错误引起的,程序员可以手动去解决的,比如判空等。
- 非运行时异常:也叫编译异常,就是Exception下除了RuntimeException以外的异常。是必须进行处理的异常,编译器会进行异常提醒的。如果不进行处理,程序编译不通过
13、日志
13.1、基本概念
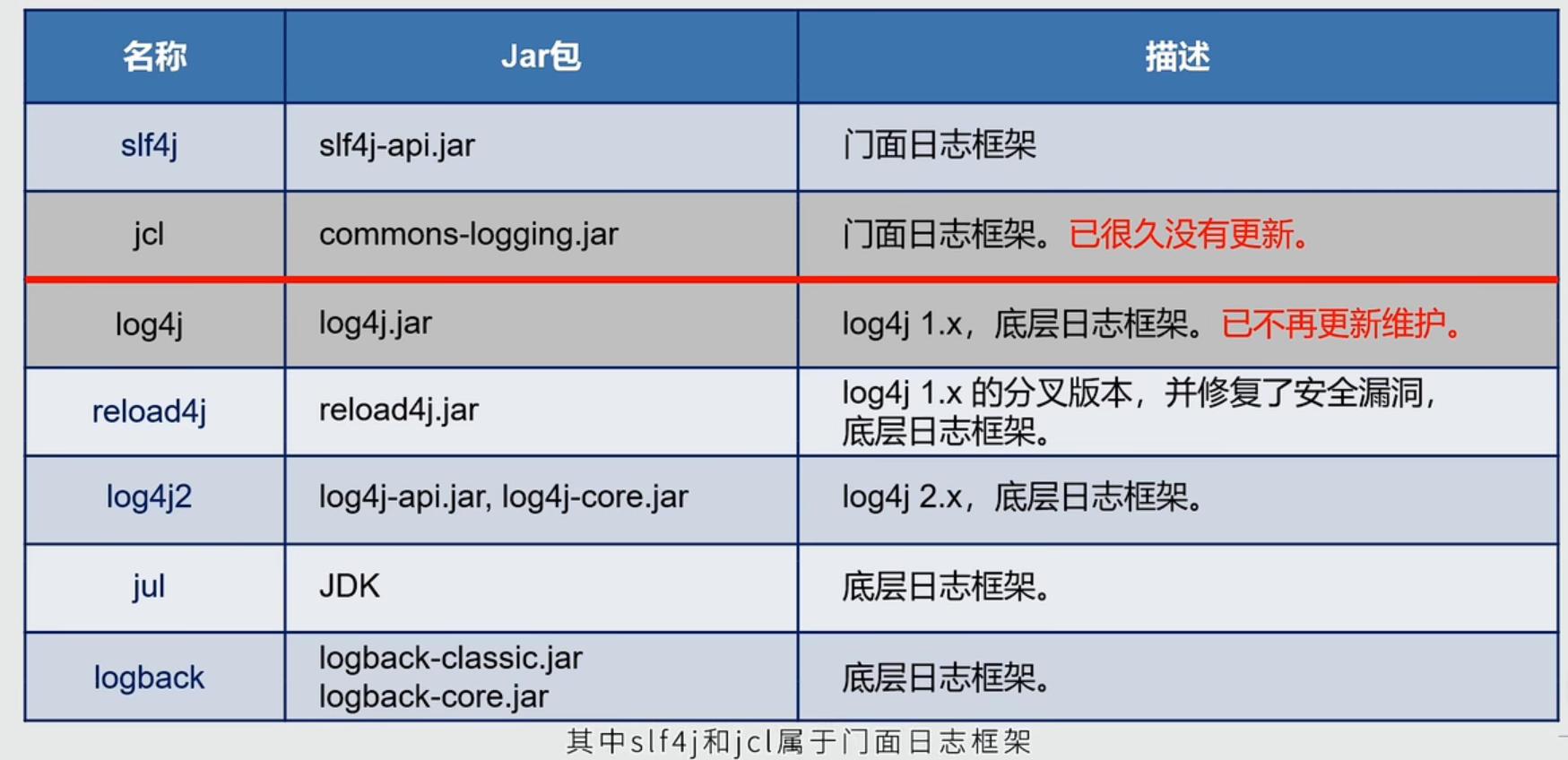
常用的组合使用方式是Slf4j与Logback组合使用,Commons Logging与Log4j组合使用。
13.2、java日志演化历史
(1)最开始出现的是 log4j,也是应用最广泛的日志系统,作者是 Ceki Gülcü,开始时,一切都是美好的。
(2)但 java 的开发主体 Sun 公司认为自己才是正统,为了干掉 log4j,在 jdk1.4 中增加了 jul(因为在 java.util.logging 包下)日志的实现,造成了目前开发者的混乱,迄今为止仍饱受诟病。
(3)各个日志系统互相没有关联,替换和统一变的非常麻烦。A 项目用 log4j 作为日志系统,但同时引了 B 项目,而 B 项目用 jul 作为日志系统,那么你的应用就得使用两个日志系统。
(4)为了搞定这个坑爹的问题,开源社区 apache 提供了一个日志框架作为日志的抽象,叫 commons-logging,也被称为 jcl(java common logging),jcl 对各种日志接口进行抽象,抽象出一个接口层,对每个日志实现都适配或者桥接,这样这些提供给别人的库都直接使用抽象层即可,较好的解决了上述问题。
(5)当年 Apache 说服 log4j 以及其他的日志来按照 commons-logging 的标准编写,但是由于 commons-logging 的类加载有点问题,实现起来也不友好,作为元老级日志 log4j 的作者再度出山,搞出了一个更加牛逼的新的日志框架 slf4j(这个也是抽象层),同时针对 slf4j 的接口实现了一套日志系统,即传说中的 logback。
(6)同时这个作者心情一好,又把 log4j 进行了改造,就是所谓的 log4j2,同时支持 jcl 以及 slf4j。